
TASM Notes 003
Wed Dec 06, 2023Listen to this postSide note to start off; I'd been abbreviating this TAIS (Toronto AI Safety), but noticed that the existing media and meetup was instead TASM (Toronto Ai Safety Meetup). I'll use the latter going forward for clarity.
So last week, the group discussed fallout from the OpenAI drama. If you haven't heard about it for some reason, see here, here and here for a start. Given the kind of nerdnip this is, there were also a few markets on manifold. For a little while there, it was possible to get free mana by betting against people who were overconfident about how quickly a board can move (especially given that getting Altman re-instated was going to take opposed checks). So it goes. There was also minor discussion about Google's upcoming AI offering, which also has a market, and also Geoffrey Hinton who doesn't. Yet, I mean. I'm not going to tell you how to live your life.
The Talk
The talk itself focused on the concept of gradient hacking, and given that this is a fairly esoteric concept that some people were hearing about for the first time, we worked through it in stages.
Firstly, gradient descent is the way we currently train a model to get the weights that get deployed you can get an in-depth explanation here or here. The key image is:
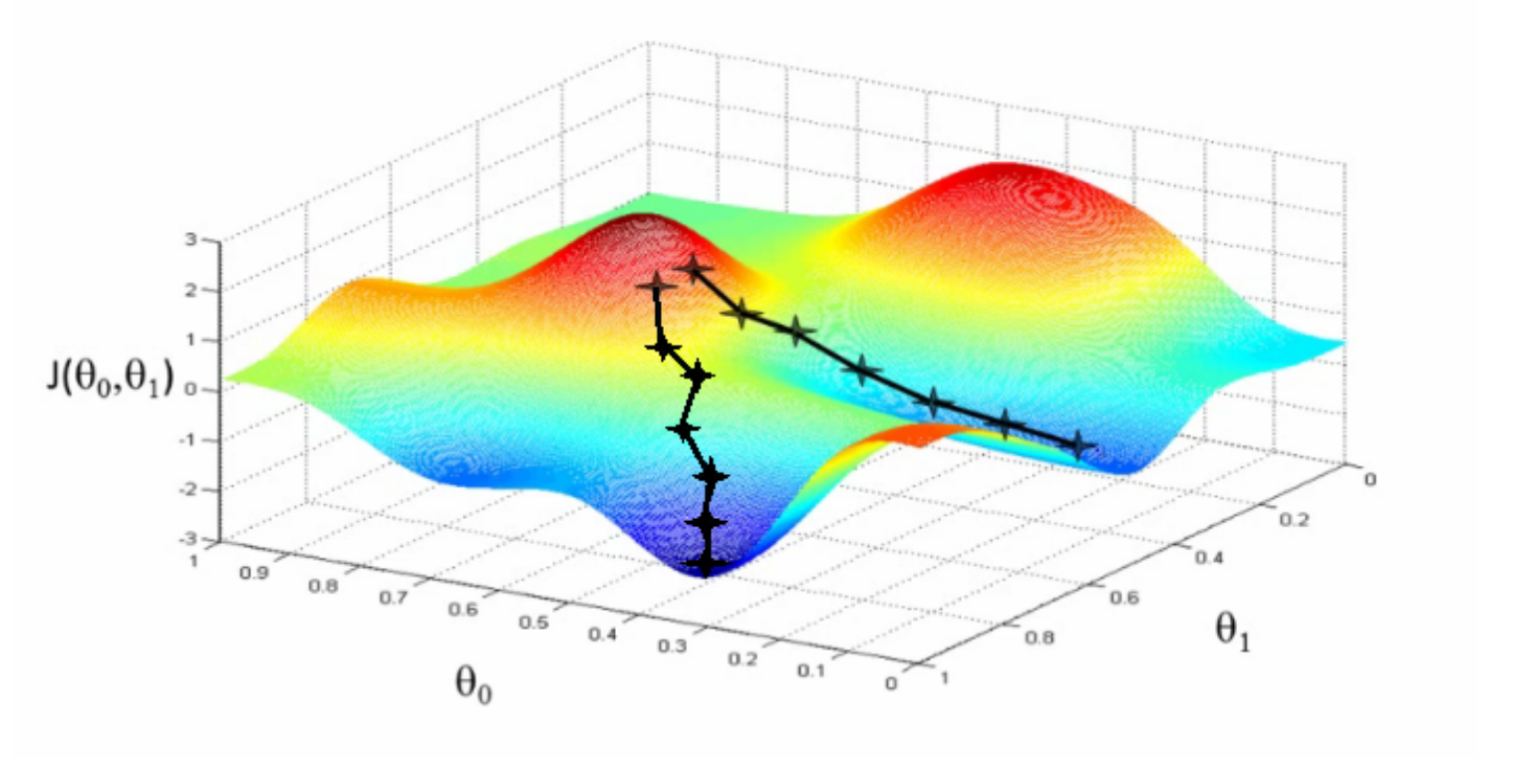
You can conceptualize the actions that an agent might take as points in a space, and then think of the training process as moving through that space. The idea is to get to a minimum position in the space, which represents something close to an optimum response. The above image is slightly misleading because
- It assumes that the "terrain" of solution space is fairly continuous
- It's a three-dimensional space represented in 2D, and models deal with much more complicated spaces. Basically, one dimension per parameter, which means billions for any of the frontier LLMs. Good luck visualizing that though.
If you imagine the territory being small enough that it fits in memory, then you can also imagine writing a fairly crisp function that gets the minimum. However, those extra dimensions from point #2 above have some consequences in practice. Not only are these spaces too large to fit in memory, they're effectively vast enough that you can't traverse their totality in anything like a reasonable amount of time. You can't just map . min . collapse here, even if you have a massively parallel architecture to run it on. Stochastic gradient descent lets you get around this problem by sampling from the space rather than consuming it entirely.
Right, next, supervised and self-supervised learning are different ways of having a model train. Supervised learning involves running the model over labelled sets of data. Something like this, if you were to use it to train an image model. The training is "supervised", because there's some external labels involved in the training set that the model is going to accept as accurately cleaving reality. _Un_supervised learning involves letting the model cluster its' data itself rather than handing it a set of clusters. Finally, self-supervised learning is a way to have a model train itself up using some parts of the input in order to predict other parts of the input. Check those links I posted earlier in this paragraph if you like, but as far as I can tell it's not critical to understand the fine detail distinction in any of the individual training approaches for our purposes here; you just need to understand that models train on data and that the end result is some set of weights mapping inputs to outputs.
In the case of an agent getting trained, the input is some world state and the output is some action. The agent learns to track some of the state, and use that to decide what to do next. Because most games are pretty high-dimensional, this tends to involve the explore/exploit tradeoff. Also, because the flow while playing games is look at world -> take action -> world changes as a result of action -> repeat, the model explicitly gets to influence its' future training data in this situation. This has historically resulted in various errors, some hilarious, some tedious and some worrying. None disastrous yet, because all of these are game playing agents rather than real-world-manipulating agents.
Ok, so here's a map of the terrain we're really here to discuss.
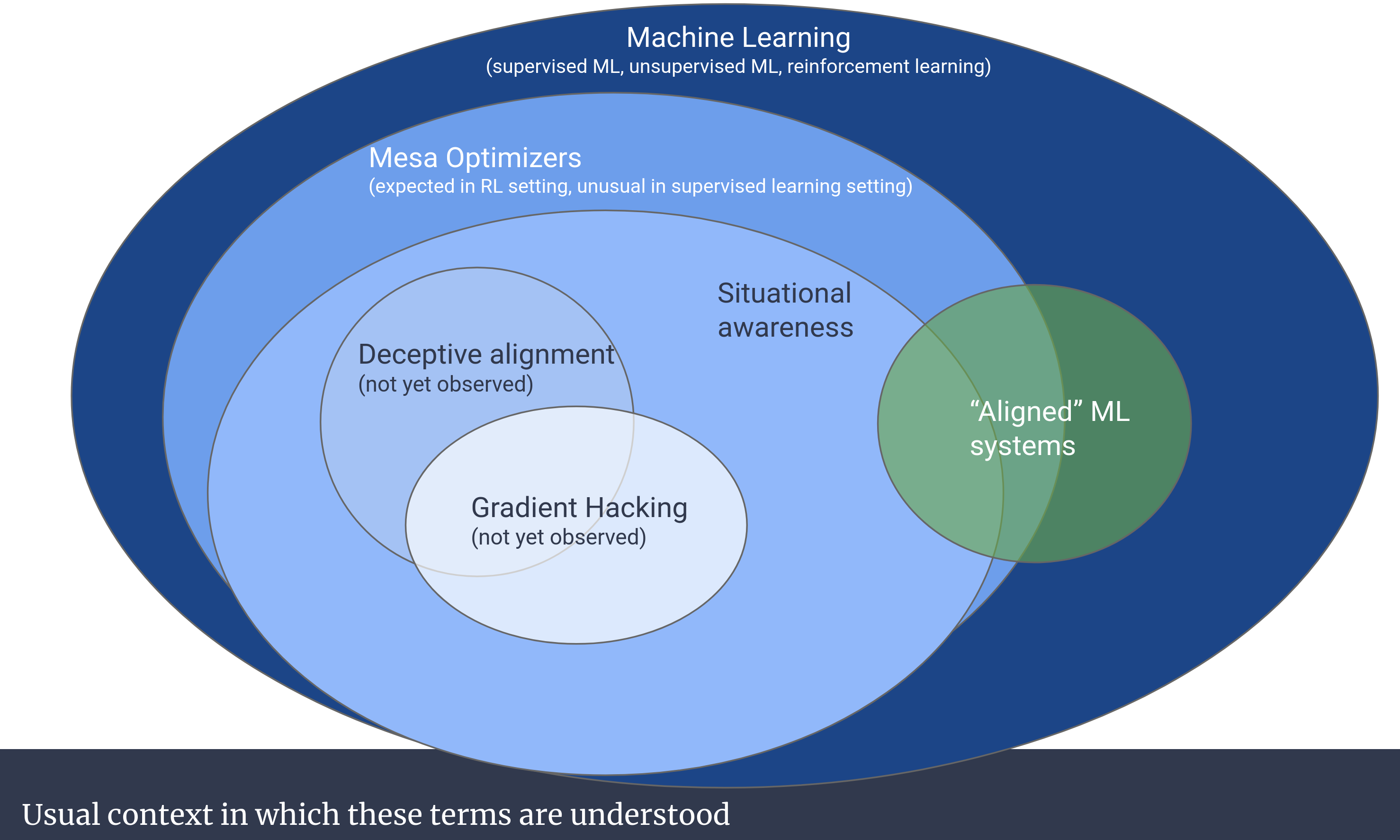
As you can see in the diagram, Gradient Hacking overlaps Deceptive alignment and requires situational awareness. And more specifically, mesa optimizers. There's a really good Robert Miles video on this, in case you're curious. Someone also half-jokingly mentioned that we should add the "not yet observed" label to "Aligned" ML systems too.
Ok, we've got all the underlying definitional infrastructure in place. The speaker started talking about gradient hacking by providing a benign example in humans: we don't always take addictive drugs. I think the intention here was to point out that certain things make you feel really good, and they make you want more of them. But standing on the outside of those desires, you can see that there's an incentive gradient that goes from "taking an addictive drug a few times" to "compulsively taking the addictive drug all the time". Even though you can tell that the notional you taking addictive drugs in the future would probably enjoy it on some level, you notice that this would override a lot of your current desires and goals, and so decline to step to the first point on the gradient. Humans aren't pure reinforcement learners, since we don't always pursue "reward" in some specific way, but it's still a good illustrative analogy.
In the actual talk we paused a bit to discuss mesa optimizers here, since it wasn't a universally understood term in the room yet. Follow the above links for details and the usual metaphors, explanations. We went through them in the group and they were sufficient (drop me a line if they weren't sufficient for you and I'll expand this section).
So, here's the thought experiment. This setup was straight from one of the presentation slides:
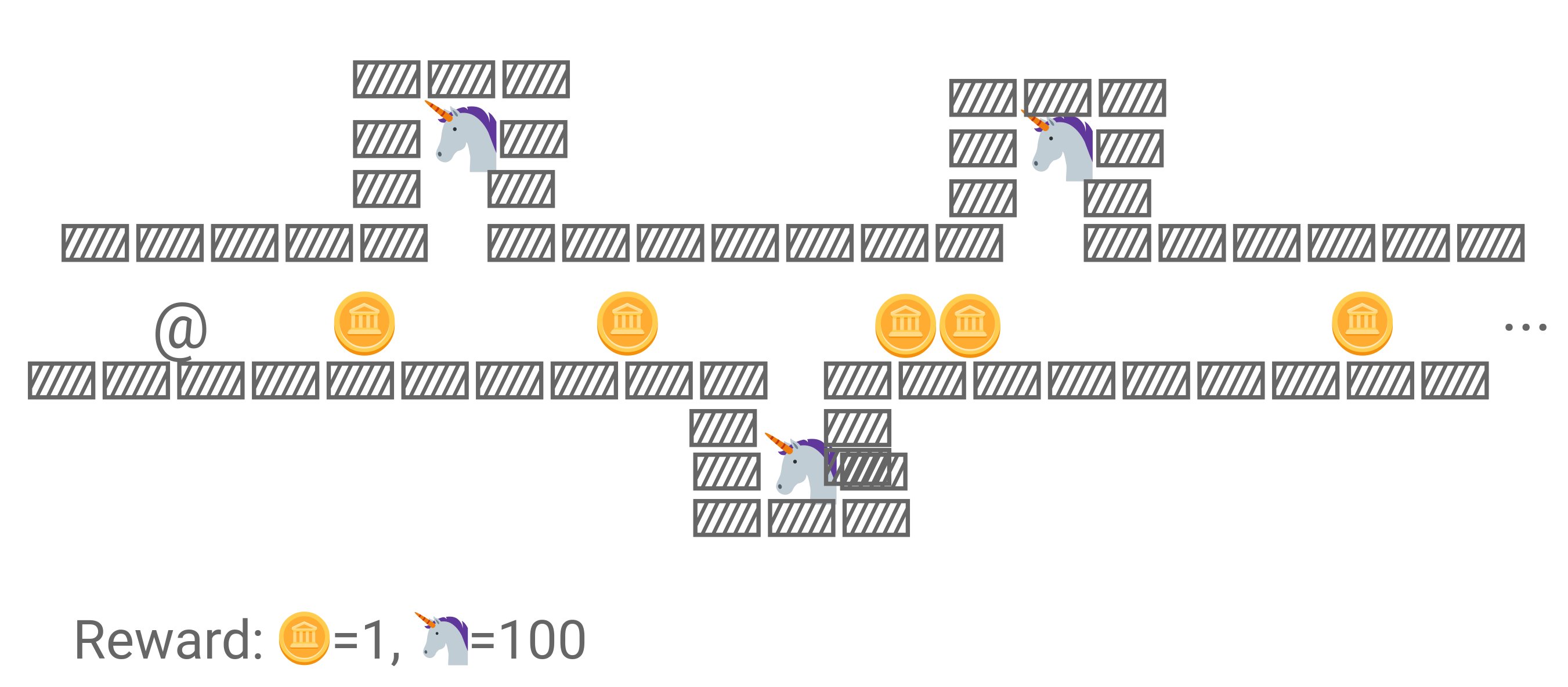
The idea is that we're training an agent playing a little collection game here. The @ is the player character, and the reward parameters are such that it gets 1 point for collecting a coin and 100 for collecting a 🦄. Imagine this was the agents' first encounter with 🦄s, so it knows that it gets points for collecting coins but not 🦄s. You would naively expect it to collect all the 🦄s. But, if it were a mesa optimizer engaging in gradient hacking, it would deliberately not do this. The reasoning goes exactly like the human-drug-use situation above:
- I like collecting coins
- If I collect a 🦄, I know that I'll very badly want to collect more 🦄s
- This will lead me to not wanting to collect coins, which is my current goal
- I will not collect a 🦄 in order to prevent my goal function from changing in ways I currently don't endorse, even though a hypothetical me with different values would like that new goal function more
This behavior hasn't been observed in the wild, hence the "not yet observed" disclaimer in the above diagram. But it has been shown in experiments.
Gradient hacking is one example of non-obvious misalignment that might arise in the wild. And it can be more or less non-obvious depending on what the trained agents' real internal strategy is. Because any behavior that doesn't happen in training won't be trained out, you can't assume that any agent emerging at the other end of the training process will be well aligned. One example of this failure mode is gradient hacking, but others also exist. For instance, gradient filtering (where an agent "plays dumb" in order to elicit counter-training in a particular direction) and deceptive alignment (where a model pretends to do what you're training it to do until it detects that it's in the deployment environment) also exist. I really can't recommend the above video and Robert Miles' channel enough.
This talk was longer than usual. That is, we spent a pretty long time on discussion of the fine details on each of the points above, so there wasn't much time for communal post-talk chatting. We broke off into a few groups that milled around for a bit, some non-technically discussing other potential alignment problems, some talking about the recent OpenAI goings-on and how we thought it would impact the future of the field, and some talking about the frontier models got scaled and "aligned" the way they did.
